MySQL 基础优化
谈 MySQL 优化不如说是 MySQL 的基础学习,本文从以下几个方面探讨 MySQL 的使用技巧。
建表优化
索引优化
SQL 优化
集群优化
MySQL 的优化思路:不查->少查->内存查->磁盘查->用索引->少排序
建表优化
定长与变长分离
常用字段和不常用字段分离
列类型选择:int > date,time > enum,char > varchar > blob,text
int 定长,没有字符集差异
time 定长,运算快,节省空间。但需要考虑时区,写 SQL 时不方便 where > ‘2005-10-12’;
enum 能起来约束值的目的,内部用整型来存储,但与 char 联查时,内部要经历串与值的转化
char 定长,需要考虑字符集和(排序)校对集
varchar, 不定长 要考虑字符集的转换与排序时的校对集,速度慢.
text/blob 无法使用内存临时表(排序等操作只能在磁盘上进行)
比如性别存储选 tinyint:
char(1) , 3个字长字节 enum(‘男’,’女’); // 内部转成数字来存,多了一个转换过程 tinyint() , // 0 1 2 // 定长1个字节.再如时间字段存储可以选择 INT 或 TIMESTAMP 或 DATETIME 类型,DATETIME 类型需要考虑时区差异造成的影响,而 INT 和 DATETIME 需要转化。具体选择要结合需求。
尽量避免用NULL()
原因: NULL不利于索引和查询,查询时
WHERE clo_name IS NULL或者WHERE clo_name IS NOT NULL要用特殊的字节来标注。在磁盘上占据的空间其实更大(mysql5.7已对null做的改进,但查询仍是不便)。加冗余地段 (触发器)
在两表关联时,比如文章表
article和评论表comment之间有关联,查询文章时想要查询文章下的评论总数,如果没有冗余字段需要联合查询,效率很低,因此可以在文章表中添加com_count冗余字段,该字段保存该文章下的评论总数。再添加和删除评论时用可以使用触发器对该字段进行修改。还有一中场景是有一个字段叫
name保存的是中文姓名,查询时经常会对该字段按照拼音排序,如果选用 GBK 字符集默认就是拼音排序,但如果其他字符集可以加一个冗余的拼音字段,以达到快速排序的效果。字符集选择
如果确认全部是中文,不会使用多语言以及中文无法表示的字符,那么GBK是首选。采用UTF-8编码会占用3个字节,而GBK只需要2个字节。
引擎选择
MySQL 中常用的引擎有 MyISAM 和 InnoDB,其中 InnoDB 支持事务,MyISAM 不支持事务,选择引擎时除了考虑事务支持以外还要考索引类型的不同,MyISAM 默认为非聚簇索引,InnoDB 为非聚簇索引。
索引优化
基本概念
主键
主键,又称主码(英语:primary key 或 unique key)。数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
从技术的角度来看,primary key和unique key有很多相似之处。但还是有以下区别:
作为 primary key 的列不能为Null。而 unique key 可以。
在一个表中只能有一个 primary key,而可以有多个 unique key。
更大的区别在逻辑设计上。primary key 一般在逻辑设计中用作记录标识,这也是设置 primary key 的本来用意。而 unique key 只是为了保证字段取值的唯一性。
索引
索引是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据,MyISAM 和 InnoDB 引擎中的索引是 B-tree,Memory 引擎中的索引是 Hash。
外键
外键(英语:foreign key,),又称外部键。其实在关系数据库中,每个数据表都是由关系来连系彼此的关系,父数据表(Parent Entity)的主键(primary key)会放在另一个数据表,当做属性以创建彼此的关系,而这个属性就是外键。
比如1:1的关系,使用主表的id作为从表的主键。
索引类型
Btree 索引和 Hash 索引
Btree 适用于范围查找,相等比较,模糊查找 (=, >, >=, <, <=, or BETWEEN operators),查找速度O(lgn)
Hash 适用于相等比较(equality comparisons: =,<=>),查找速度 O(1),只能在 Memory 引擎中使用。
【误区】 在where条件常用的列上都加上索引
例:查询第3个栏目下 art_id 大于 where cat_id = 3 and art_id > 100 ; 误: cat_id 上,和, art_id 上都加上索引. 错: 只能用 上cat_id 或 art_id 索引,因为索引是相互独立的,同时只能用上 1 个。联合索引
如果 where 条件是根据多列进行筛选的,那么应该在多个列上建立一个索引,这就是联合索引。使用联合索引要注意建立时列的顺序,只有前一列上的索引被使用后一列索引才能被使用。如在 c1,c2,c3,c4 上建立联合索引
create table t4 ( c1 tinyint(1) not null default 0, c2 tinyint(1) not null default 0, c3 tinyint(1) not null default 0, c4 tinyint(1) not null default 0, c5 tinyint(1) not null default 0, index c1234(c1,c2,c3,c4) );以下情况分别使用到的索引
A where c1=x and c2=x and c4>x and c3=x B where c1=x and c2=x and c4=x order by c3 C where c1=x and c4= x group by c3,c2 D where c1=x and c5=x order by c2,c3A 中使用到了4个长度的键
B 中查找使用 c1,c2,排序使用 c3
C 中只有查找使用到 c1
D 中查找使用 c1,分组使用 c2,c3
聚簇索引和非聚簇索引
聚簇索引(也叫聚集索引)是一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。简单理解就是主键和数据存储在一起,其他普通索引是对主键的引用,InnoDB 就属于聚簇索引。
非聚簇索引是主键和其他普通索引都单独存储,索引是对数据行的引用。
优势: 根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势: 如果碰到不规则数据插入时,造成频繁的页分裂。
因此对于 InnoDB 而言,因为节点下有数据文件,因此节点的分裂将会比较慢。对于innodb的主键,尽量用整型,而且是递增的整型。如果是无规律的数据,将会产生的页的分裂,影响速度。
索引使用技巧
索引覆盖
索引覆盖是指如果查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要回行到磁盘再找数据。这种查询速度非常快,称为”索引覆盖”。
索引的长度
理想的索引应该是
查询频繁、区分度高、长度小、尽量能覆盖常用查询字段,比如在性别中建立索引是没有太大意义的,具体案例:https://www.v2ex.com/t/296130如果针对 char 类型字段建立索引,当字段长度太大时应根据查询需要截取部分长度建立索引(如果左模糊查询较多应从左开始建立索引),截取长度可以根据区分度来选择:
mysql> select count(distinct left(word,2))/count(*) from tableName;冗余索引
冗余索引是指2个索引所覆盖的列有重叠, 称为冗余索引
比如文章与标签表
+------+-------+------+ | id | artid | tag | +------+-------+------+ | 1 | 1 | PHP | | 2 | 1 | nux | | 3 | 2 | SQl | | 4 | 2 | Orac | +------+-------+------+在实际使用中,有 2 种查询
artid--- 查询文章的 ---tag tag--- 查询文章的 ---artid select tag from t11 where artid=2; select artid from t11 where tag='PHP';这种查询方式在博客中是很常用的,如果利用建立联合索引往往可以使用索引覆盖达到高效查询。
避免隐式转换
隐式转换是指 SQL 查询条件中的传入值与对应字段的数据定义不一致导致索引无法使用。常见隐士转换如字段的表结构定义为字符类型,但 SQL 传入值为数字;或者是字段定义 collation 为区分大小写,在多表关联的场景下,其表的关联字段大小写敏感定义各不相同。隐式转换会导致索引无法使用,进而出现上述慢 SQL 堆积数据库连接数跑满的情况。
由于 MySQL 不支持函数索引,在开发时要避免在查询条件加入函数,例如 date(gmt_create)。
SQL 优化
使用 profiling 查看执行时间
使用 explain 查看执行计划
LIMIT 优化
limit offset,N这是一个常见的问题https://www.v2ex.com/t/296130,当offset非常大时, 效率极低,
原因是 MySQL 并不是跳过 offset 行,然后单取 N 行,而是取 offset+N 行,返回放弃前 offset 行,返回N行。当offset越大时,效率越低,为了避免这种情况可以从业务上去解决,不允许翻过100页,以百度为例,一般只允许翻页到 70 页左右。
不用 offset, 用条件查询,如
where id > offset limit N
,这样做的缺陷是如果 id 缺失(某条记录被删除)将导致查询结果又偏差,但大数据量下的翻页牺牲一些准确度换取性能是可以的,如果非要准确度可以对数据进行逻辑删除而不是物理删除。如果非要用 offset 可以使用延迟关联。
# 先用索引查出 id select id from tableName limit 5000000,10 # 在连接查询,完整 SQL 如下 select * from tableName inner join (select id from tableName limit 5000000,10) as tmp using(id);
COUNT 优化
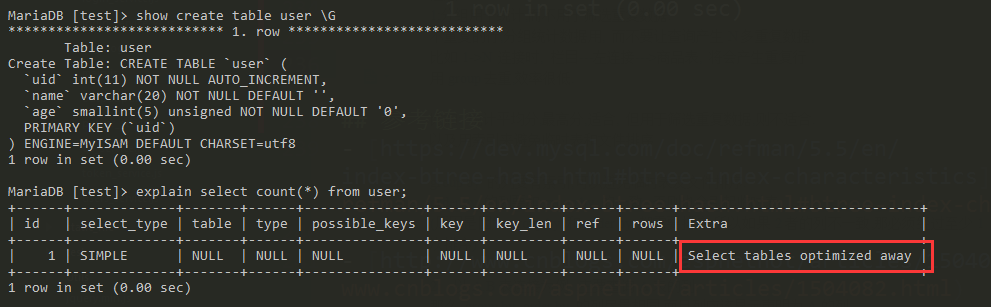
MyISAM 中对 count 进行了优化,count 统计时直接从表中读取值。
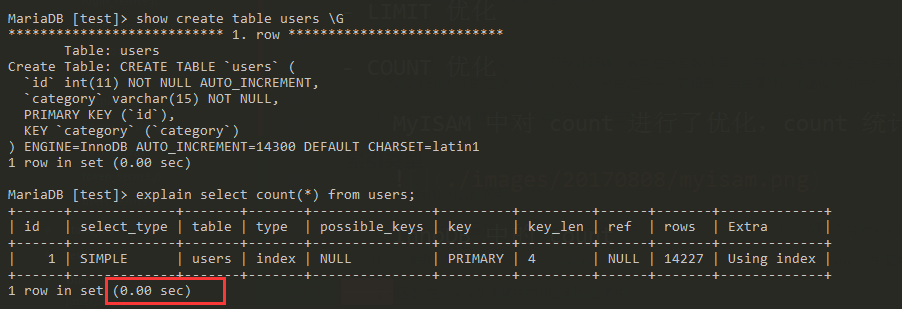
InnoDB 中的 count 使用索引统计

注意索引会被缓存到内存中,所以再次执行时比第一次快很多:
尽量避免 where 条件的 count 特别是条件列中没有索引的时候查询会更加慢。
MySQL 集群优化策略
读写分离优化策略
典型问题:
有一业务场景,经过测试,读写比为1:20,请根据读写比,合理设置优化方案.
根据写数据/读数据的比例,(Insert/update/delelte) / (select)
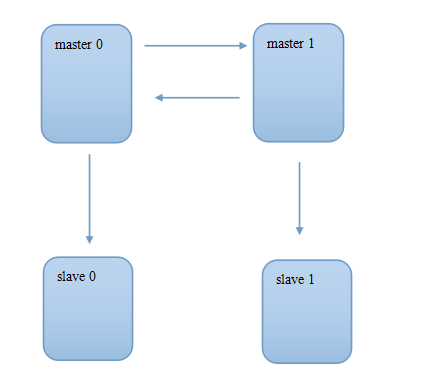
主从复制
实现步骤大概如下,具体请查阅官方文档:
首先确保主服务器打开二进制日志功能。这样,主服务器一旦有数据变化,立即产生二进制日志。
从服务器也需要开启二进制日志和 relay 日志功能。这样可以从主服务器读取 binlog, 并产生 relaylog。
在主服务器建立一个从服务器的账号,并授予读 binlog 的权限。
指定从服务对应的主服务器,开启从服务器。
主主复制
从服务器一是起到备份作用,二是起到分担查询压力的作用,如果一台服务器不足以承当写的压力可以配置多台服务器共同承担写任务,他们之间的数据可以相互复制,他们的关系是平等的。